

In this article, we are going to explore one of the most popular machine learning algorithms in realtime data streaming, online learning. Not only will you learn some theory behind algorithms such as Stochastic Gradient Descent, but we’ll also build a machine learning model that can learn in realtime from a data stream. Whether you are a beginner or advanced machine learning programmer, you will easily understand the utility behind a model that can stay up to spec with dynamic datasets like realtime IoT data streams.
What is Machine Learning?
Machine Learning is simply the intersection of Statistics and Computer Science. Traditionally, a statistical computation is performed on a small data set in order to find a line of best fit (correlation). Linear Regression (y = mx + b) is the simplest statistical method, but more complicated methods are used (ex. gradient descent) for more complex data sets.
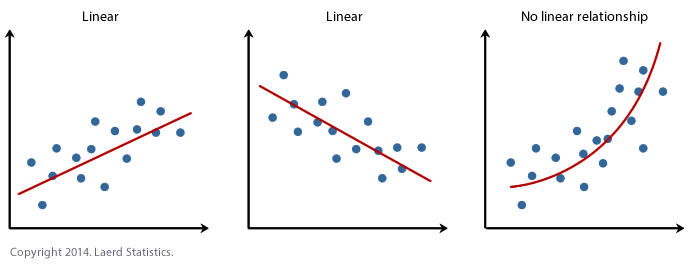
Source 7/18/19
We now live in the time of Big Data where there are enormous data sets that require millions to trillions of statistical computations, of which only a computer can compute; however, even computers can take ages to find an accurate statistical model if the data set is too large and complex. This is because traditional machine learning models must “fit” their equations on the entire data set at once.
This is far too time-consuming and costly for companies that require fast deployment of their models that must be re-factored frequently to keep up with volatile data sets (i.e. stock trading companies).
Online Learning
In the past couple of years, a specific type of machine learning called online learning has become extremely popular in the world of realtime data infrastructure. Unlike traditional machine learning models, the statistical methods performed in online learning “partially fit” their equations to subsets of the overall dataset.
This allows for a multitude of advantages:
- Fast deployment of models
- Models can be constantly updated with new chunks of data
- Can use machines with smaller memory sizes since not all the data is required at once
The main advantage we’re going to exploit today is the ability to funnel a stream of realtime data to a machine learning model. The model will adjust and update itself upon each new chunk from the data flow and will “forget” old data based on a specified time frame. We are going to use PubNub as our Data Stream Network based on the framework design below.
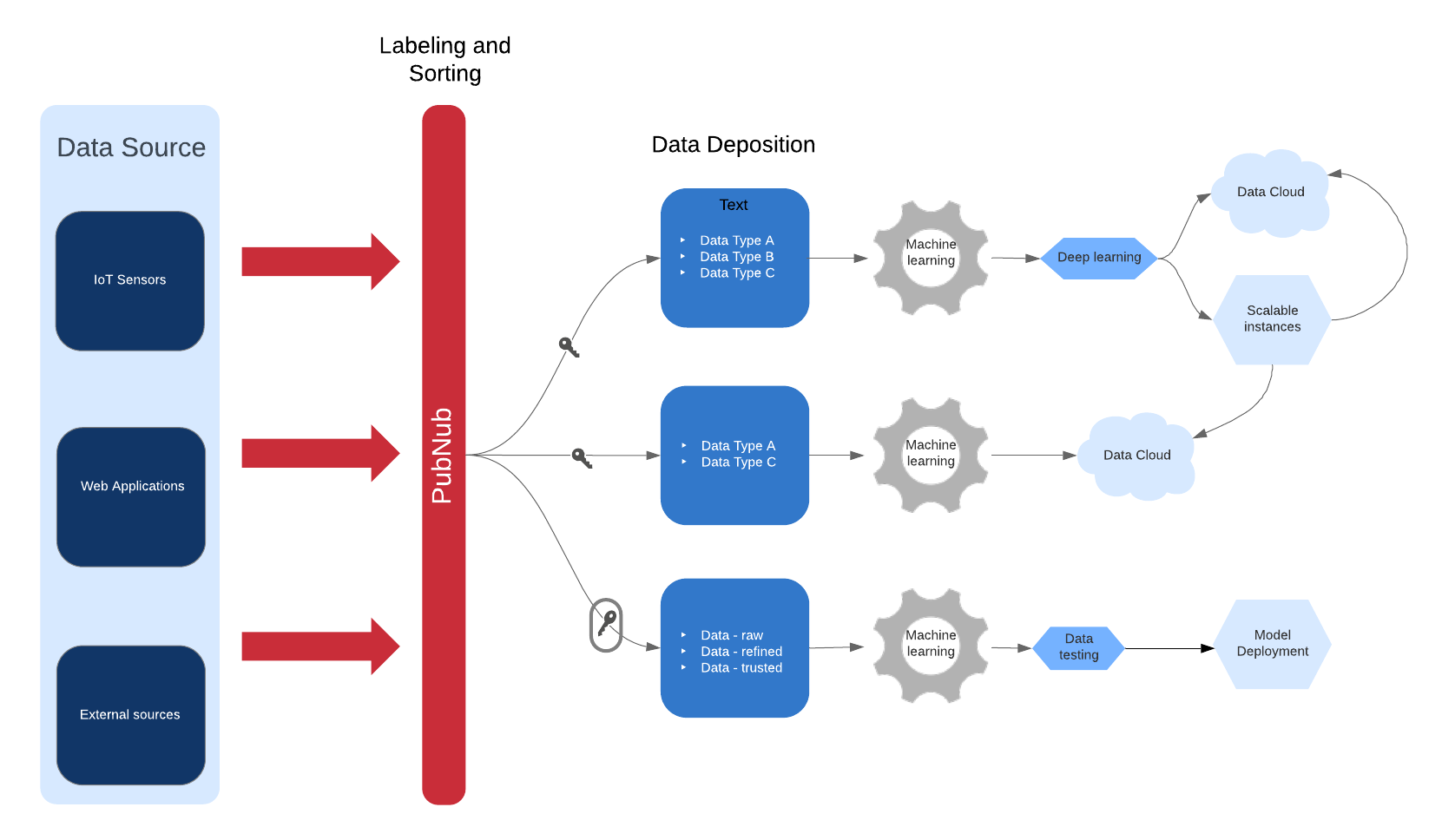
In this project, we are going to use Stochastic Gradient Descent as our choice of online learning statistical method. In standard gradient descent, we define a function to describe the relationship between the independent and dependent variables of our dataset. We then define a cost function that represents the statistical error of our function.
We can represent that cost function as a 3-dimensional surface where the global minimum is the cost function’s minimum. You can imagine the cost function looking something like a giant bowl (top of the bowl is high cost and the bottom is minimal cost). Through repeated iterations of GD calculations, the cost function moves down the bowl until it reaches the bottom of the bowl (minimum). Unfortunately, this process requires many iterations and takes a very long time to compute large data sets.

Source 7/18/19
In Stochastic (random) Gradient descent, we iterate down the bowl in a random fashion. Unlike GD, which traverses down the bowl smoothly, SGD zigzags down the bowl and can even bounce in and out of the minimum, which makes it “noisy”; however, with very large datasets, SGD converges to the minimum in far less iterations than GD and still gives a good approximation of the global minimum.

Python Code for Your Online Machine Learning System
Before jumping right into the code, be sure you sign up for a free PubNub account so we don’t run into any issues later.
For guidance, go check out this project’s repository.
Step 1: PubNub
We begin this project by setting up PubNub as our Data Stream Network as this will serve as the backbone of data transfer for our machine learning algorithm. PubNub will be responsible for facilitating our stream of realtime data for our algorithm to incrementally consume and learn.
Since we will be building our algorithm in Python, we’ll be using PubNub’s Python SDK. In your terminal, type:
pip install 'pubnub>=4.1.4'
Next, create a python file and import the PubNub dependencies.
from pubnub.callbacks import SubscribeCallback from pubnub.pnconfiguration import PNConfiguration from pubnub.pubnub import PubNub from pubnub.enums import PNOperationType, PNStatusCategory
Instantiate a PubNub instance with the Publish and Subscribe keys given to you when you made your PubNub account.
pnconfig = PNConfiguration() pnconfig.subscribe_key = "YOUR SUBSCRIBE KEY" pnconfig.publish_key = "YOUR PUBLISH KEY" pnconfig.ssl = False pubnub = PubNub(pnconfig)
In order to Publish our stream of realtime data, we will need a publishing call back implemented like so:
def publish_callback(result, status):
pass
# Handle PNPublishResult and PNStatus
NOTE: To simplify this tutorial demo, we are publishing and subscribing realtime data in the same Python file. In practice, data would be published from an offsite producer and the client program containing the machine learning algorithm would subscribe to the data.
Now to subscribe to the data stream, we need to implement a subscriber callback function to handle incoming messages.
class MySubscribeCallback(SubscribeCallback):
def status(self, pubnub, status):
pass
# The status object returned is always related to subscribe but could contain
# information about subscribe, heartbeat, or errors
# use the operationType to switch on different options
if status.operation == PNOperationType.PNSubscribeOperation \
or status.operation == PNOperationType.PNUnsubscribeOperation:
if status.category == PNStatusCategory.PNConnectedCategory:
pass
# This is expected for a subscribe, this means there is no error or issue whatsoever
elif status.category == PNStatusCategory.PNReconnectedCategory:
pass
# This usually occurs if subscribe temporarily fails but reconnects. This means
# there was an error but there is no longer any issue
elif status.category == PNStatusCategory.PNDisconnectedCategory:
pass
# This is the expected category for an unsubscribe. This means there
# was no error in unsubscribing from everything
elif status.category == PNStatusCategory.PNUnexpectedDisconnectCategory:
pass
# This is usually an issue with the internet connection, this is an error, handle
# appropriately retry will be called automatically
elif status.category == PNStatusCategory.PNAccessDeniedCategory:
pass
# This means that PAM does not allow this client to subscribe to this
# channel and channel group configuration. This is another explicit error
else:
pass
# This is usually an issue with the internet connection, this is an error, handle appropriately
# retry will be called automatically
elif status.operation == PNOperationType.PNSubscribeOperation:
# Heartbeat operations can in fact have errors, so it is important to check first for an error.
# For more information on how to configure heartbeat notifications through the status
# PNObjectEventListener callback, consult <link to the PNCONFIGURATION heartbeart config>
if status.is_error():
pass
# There was an error with the heartbeat operation, handle here
else:
pass
# Heartbeat operation was successful
else:
pass
# Encountered unknown status type
def presence(self, pubnub, presence):
pass # handle incoming presence data
def message(self, pubnub, message):
#handle incoming message data
Below, instantiate the callback listener and subscriber with respect to a specified channel like so:
pubnub.add_listener(MySubscribeCallback())
pubnub.subscribe().channels('YOUR CHANNEL').execute() Step 2: Data Pre-Processing and Data Streaming
As with any machine learning model, “data trumps everything,” so we’re going to need a lot of it. Fortunately for us, the sklearn library has a convenient tool to generate very large synthetic datasets that we can use to train our model.
Create a new python file in your project directory and use this code to generate the dataset CSV.
from sklearn.datasets import make_classification
X,y = make_classification(n_samples=10**7, n_features=5, n_informative=3, random_state=101)
D = np.c_[y,X]
np.savetxt('huge_dataset_10__7.csv', D, delimiter=",") # the saved file should be around 1,46 GB
del(D, X, y) Now that we have a dataset to work with, let’s go back to our original python file and parse the data into manageable chunks.
In order to read in the data from the CSV, we’re going to use the Pandas library. We’re also going to use Python’s Numpy library to convert the data into a data structure that our machine learning algorithm can understand. At the top of your Python file, import the libraries.
import pandas as pd import numpy as np
Now we are going to read in the data in chunks. Each chunk will contain 200 rows (observations) along with all the columns (attributes) of each observation.
streaming = pd.read_csv('huge_dataset_10__7.csv', header=None, chunksize=200) Then we will iterate over the entire datasets in chunks, formatting and publishing each chunk over our Data Stream Network.
for n,chunk in enumerate(streaming):
chunk = np.array(chunk).tolist() #convert each chunk into a numpy array
dictionary = {'chunk': str(chunk), 'n': n} #stringify each array as well as chunk number to prepare for publishing
pubnub.publish().channel('YOUR CHANNEL').message(dictionary).pn_async(publish_callback) #publish chunk over PubNub Step 3: Machine Learning
We just finished building the actual stream of data so now it’s time to tap into that stream to feed into our machine learning algorithm. Each chunk that is published to the stream will incrementally update and improve our model’s performance. In order to make sure that our algorithm is truly up to date with realtime data, we can specify the model’s learning rate, which will determine how quickly the model will “forget” old information and only base its predictions on contemporary data.
The first thing we need to do is create some class variables and instances for our Subscriber Callback to use upon each incoming message. This includes the ML model itself as we need to reuse the previous model to update it. We will also use a MinMax Scaler to scale the incoming data so that large fluctuations in data values won’t skew our results.
At the very top of the subscriber callback, declare these variables and instances:
m = -1 #chunk number learner = SGDClassifier(loss='log', learning_rate = 'optimal') #Machine Learner minmax_scaler = MinMaxScaler(feature_range=(0, 1)) #data value scaler cumulative_accuracy = list() #list to store the statistical accuracy of our model throughout the learning process
Now in your message event handler place this block of code:
def message(self, pubnub, message):
self.m += 1 #increment chunk count
chunk = literal_eval(message.message['chunk']) #de-stringify the message's matrix chunk into a python array
chunk = np.array(chunk) #convert the chunk into a numpy array
print('learning epoch #', self.m) #display the epoch the algorithm is currently learning from
if self.m == 0: #Initially fit the scaler to the first chunk's Independent variables
minmax_scaler.fit(chunk[:,1:])
X = minmax_scaler.transform(chunk[:,1:]) #Scale and transform the Chunk's Independent variables into a separate matrix
X[X>1] = 1 #Truncate the matrix values that exceed 1
X[X<0] = 0 #Truncate the matrix values that are negative
y = chunk[:,0] #Create a separate matrix of all the dependent variables
if self.m > 8 : #Begin storing the model's statistical accuracy after the 8th Chunk
cumulative_accuracy.append(learner.score(X,y))
learner.partial_fit(X,y,classes=[0,1]) #Update the learner, specifying that there are 2 classes of dependent variables
print('Progressive validation mean accuracy %0.3f' % np.mean(cumulative_accuracy)) #display the learner accuracy score As you can see above, we performed the following steps:
- Formatted the chunk into a workable data structure
- Fit and transformed the chunk to our scaler
- Broke the original chunk of data into two matrices X (independent variables) and y (dependent variables).
- Partially fit the two matrices to our learner to incrementally learn from
- Display the accuracy of the model with each successive update
Terminal Output
Congratulations! If you’ve made it this far it’s time to see the fruits of your labor! You should expect to see your terminal printing every learning epoch (processed chunk) as well as the current accuracy of the algorithm: If we let the algorithm run for a while, the validation mean accuracy converges to roughly 70%, which is not bad for a synthetically generated dataset!
If we let the algorithm run for a while, the validation mean accuracy converges to roughly 70%, which is not bad for a synthetically generated dataset!
Conclusion
Feel free to send us any of your questions, concerns, or comments at devrel@pubnub.com.
If you’re still hungry for more PubNub Machine Learning content, here are some other articles that you may be interested in:
Try PubNub today!





